 [Hadoop] hadoop1.1.2分布式环境搭建 日期:2016-07-19 23:09:11 点击:143 好评:0
[Hadoop] hadoop1.1.2分布式环境搭建 日期:2016-07-19 23:09:11 点击:143 好评:0
hadoop1.1.2分布式安装 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式...
 [Memcached] Nginx+Tomcat+Memcached负载均衡集群服务搭建 日期:2016-07-14 17:02:49 点击:181 好评:0
[Memcached] Nginx+Tomcat+Memcached负载均衡集群服务搭建 日期:2016-07-14 17:02:49 点击:181 好评:0
Nginx+Tomcat+Memcached负载均衡集群服务搭建 操作系统:CentOS6.5 本文档主要讲解,如何在CentOS6.5下搭建Nginx+Tomcat+Memcached负载均衡集群服务器,Nginx负责负载均衡,Tomcat负责实际服务,Memcached负责同步Tomcat的Session,达到Session共享的目的。...
[Memcached] memcache客户端“一致性hash算法”设置 日期:2016-07-14 17:02:21 点击:55 好评:0
memcache客户端一致性hash算法设置 Memcache 修改php.ini添加: [Memcache] Memcache.allow_failover = 1 Memcache.hash_strategy =consistent Memcache.hash_function =crc32 ini_set方法: Ini_set(memcache.hash_strategy, consistent ); Ini_set(memcach...
[Memcached] memcached集群架构 日期:2016-07-14 17:01:51 点击:72 好评:0
集群架构方面的问题 o memcached是怎么工作的? o memcached最大的优势是什么? o memcached和MySQL的query cache相比,有什么优缺点? o memcached和服务器的local cache(比如PHP的APC、mmap文件等)相比,有什么优缺点? o memcached的cache机制是怎样的...
[Memcached] memcached集群负载均衡 日期:2016-07-14 17:01:19 点击:155 好评:0
memcached是针对数据库的缓存软件 能有效降低数据库的负载 下面是何如将多个memcached做成集群负载均衡,让memcached变的更高可用 一、安装步骤: 1、编译安装libevent: 1234 tar zxvf libevent-1.4.9-stable.tar.gzcd libevent-1.4.9-stable/./configure --...
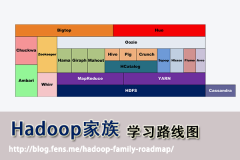 [Hadoop] Hadoop家族学习路线图 日期:2016-07-14 16:14:17 点击:141 好评:0
[Hadoop] Hadoop家族学习路线图 日期:2016-07-14 16:14:17 点击:141 好评:0
Hadoop家族系列文章 ,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。 从2011年开...
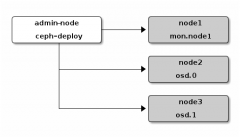 [Ceph] CentOS7环境下Ceph安装部署 日期:2016-07-14 15:08:18 点击:125 好评:0
[Ceph] CentOS7环境下Ceph安装部署 日期:2016-07-14 15:08:18 点击:125 好评:0
Ceph简介 eph的设计目标是是在廉价的存储介质上构建具有 high performance, high scalibility, high available, 提供统一存储,分文件存储,块存储,对象存储。最近看了相关文档觉得挺有意思,而且它已经能为openstack提供块存储,非常贴合主流趋势。 Ceph...
[Ceph] Ceph 单/多节点 安装小结 Power by CentOS 6.x 日期:2016-07-14 15:07:45 点击:172 好评:0
概述 Docs : http://docs.ceph.com/docs Ceph是一个分布式文件系统,在维持POSIX兼容性的同时加入了复制和容错功能。Ceph最大的特点是分布式的元数据服务器,通过CRUSH(Controlled Replication Under Scalable Hashing)这种拟算法来分配文件的location。Ce...
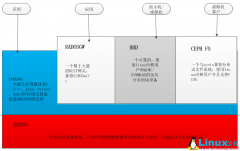 [Ceph] Ceph分布式存储系统 日期:2016-07-14 15:05:54 点击:142 好评:0
[Ceph] Ceph分布式存储系统 日期:2016-07-14 15:05:54 点击:142 好评:0
Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能及高可靠性。Ceph其命名和UCSC(Ceph的诞生地)的吉祥物有关,这个吉祥物是Sammy,一个香蕉色的蛞蝓,就...
[Ceph] Ceph的安装过程 日期:2016-07-14 15:04:06 点击:83 好评:0
前面一段时间公司要求找一个分布式软件,于是就看了下开源的ceph,在官网上http://ceph.com/download/下载了ceph-0.52.tar.gz源码包。 这儿记录了下自己安装的过程: 操作系统使用的是: CentOS-6.3-x86_64; 一、先安装一些编译常用工具,也是本次编译所需要...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...
一、 Apache、Tomcat集群和负载均衡所需资源软件(附下载地址): a) apache_2.0.55-win...
不对的地方,欢迎大家拍砖。 现在有如下三台服务器: 10.57.22.201(做负载均衡配制)(...
一、试验拓扑 二、环境描述 负载均衡器: eth0 192.168.152.139 VIP : 192.168.152.2...