 [Hadoop] Hadoop 集群安装与配置 日期:2017-07-21 20:45:29 点击:55 好评:0
[Hadoop] Hadoop 集群安装与配置 日期:2017-07-21 20:45:29 点击:55 好评:0
1 Hadoop 是什么? Apache Hadoop 是一个支持数据密集型分布式应用程序的开源软件框架,能在大型集群上运行应用程序。Hadoop 框架实现了 MapReduce 编程范式,把应用程序分成许多小部分,每个部分能在任意节点上运行。并且 Hadoop 提供了分布式文件系统存储...
 [负载均衡SLB] 用NginX+keepalived实现高可用的负载均衡 日期:2017-02-12 16:04:53 点击:77 好评:0
[负载均衡SLB] 用NginX+keepalived实现高可用的负载均衡 日期:2017-02-12 16:04:53 点击:77 好评:0
Table of Contents 1 规划和准备 2 安装 3 配置 3.1 配置NginX 3.2 配置keepalived 3.3 让keepalived监控NginX的状态 4 还可以做什么 5. 补充:SSL配置(update:2013-05-17) 1规划和准备 需要统一接入的应用系统 应用系统 域名/虚拟目录 应用服务器及URL svn...
 [Hadoop] Hadoop2.x下安装HBase 日期:2017-02-05 23:39:52 点击:71 好评:0
[Hadoop] Hadoop2.x下安装HBase 日期:2017-02-05 23:39:52 点击:71 好评:0
环境:CentOS6.5 Hadoop2.5.2 HBase1.0.0 1.安装好 hadoop 集群,并启动 [grid@hadoop4 ~]$ sh hadoop-2.5.2/sbin/start-dfs.sh [grid@hadoop4 ~]$ sh hadoop-2.5.2/sbin/start-yarn.sh 查看 hadoop 版本: [grid@hadoop4 ~]$ hadoop-2.5.2/bin/hadoop versi...
 [Hadoop] Hadoop 2.0集群配置详细教程 日期:2017-02-05 23:37:18 点击:82 好评:0
[Hadoop] Hadoop 2.0集群配置详细教程 日期:2017-02-05 23:37:18 点击:82 好评:0
前言 Hadoop2.0介绍 Hadoop是 apache 的开源 项目,开发的主要目的是为了构建可靠,可拓展 scalable ,分布式的系 统, hadoop 是一系列的子工程的 总和,其中包含 1. hadoop common : 为其他项目提供基础设施 2. HDFS :分布式的文件系 统 3. MapReduce :...
 [Hadoop] Hadoop完全分布式搭建 日期:2017-02-05 23:35:28 点击:56 好评:0
[Hadoop] Hadoop完全分布式搭建 日期:2017-02-05 23:35:28 点击:56 好评:0
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。 对于Hadoop的集群来讲,...
[Hadoop] CentOS7安装Hadoop2.7完整流程 日期:2017-02-05 22:27:28 点击:65 好评:0
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs、mapreduce等主从关系。 1、环境,3台CentOS7,64位,Hadoop2.7需要64位Linux,CentOS7 Minimal的ISO文件只有600M,操作系统十几分钟就可以安装完...
[服务器集群] etcd 集群管理维护 日期:2017-02-03 17:07:58 点击:75 好评:0
官方网站: https://github.com/coreos/etcd/ 环境: CentOS7 etcd-3.0.4 3节点集群示例 etcd1:192.168.8.101 etcd2:192.168.8.102 etcd3:192.168.8.103 一.安装etcd(所有节点) curl -L https://github.com/coreos/etcd/releases/download/v3.0.4/etcd-v3.0.4-l...
 [服务器集群] LVS-DR模型实现负载均衡 日期:2017-02-02 00:35:06 点击:91 好评:0
[服务器集群] LVS-DR模型实现负载均衡 日期:2017-02-02 00:35:06 点击:91 好评:0
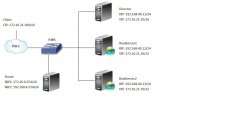
前言 前篇文章我们主要讲解了LVS-DR模型的架构方式以及如何实现,想了解的小伙伴点这个LVS-NAT模型实现负载均衡,今天我们来进行实践的LVS中三种模型中的DR模型的架构以及实现方式。(实验环境还以Web集群作为实验对象) 环境 此处我们LVS-DR模型环境架构也用...
 [服务器集群] LVS-NAT模型实现负载均衡 日期:2017-02-02 00:31:09 点击:97 好评:0
[服务器集群] LVS-NAT模型实现负载均衡 日期:2017-02-02 00:31:09 点击:97 好评:0
前言 前篇文章我们主要讲解了LVS的理论知识,包括LVS来源、宗旨、三种模型的架构以及LVS内核空间的十种算法,今天我们来进行实践的LVS中三种模型中的NAT模型的架构以及实现方式。(实验环境以Web集群作为实验对象) 环境 此处我们LVS-NAT模型环境架构为三台Lin...
 [服务器集群] Linux服务器集群LVS 日期:2017-02-02 00:08:38 点击:76 好评:0
[服务器集群] Linux服务器集群LVS 日期:2017-02-02 00:08:38 点击:76 好评:0
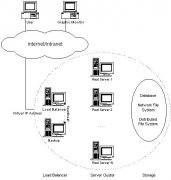
本文主要介绍了Linux服务器集群系统LVS(Linux Virtual Server),并简单描述下LVS集群的基本应用的体系结构以及LVS的三种IP负载均衡模型(VS/NAT、VS/DR和VS/TUN)的工作原理,以及它们的优缺点和LVS集群的IP负载均衡软件IPVS在内核中实现的各种连接调度算法...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...
一、 Apache、Tomcat集群和负载均衡所需资源软件(附下载地址): a) apache_2.0.55-win...
不对的地方,欢迎大家拍砖。 现在有如下三台服务器: 10.57.22.201(做负载均衡配制)(...
一、试验拓扑 二、环境描述 负载均衡器: eth0 192.168.152.139 VIP : 192.168.152.2...