 [Kubernetes] kubernetes集群配置serviceaccount 日期:2018-05-09 11:50:33 点击:183 好评:0
[Kubernetes] kubernetes集群配置serviceaccount 日期:2018-05-09 11:50:33 点击:183 好评:0
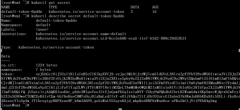
Kubernetes API的其它服务。Service Account它并不是给kubernetes集群的用户使用的,而是给pod里面的进程使用的,它为pod提供必要的身份认证。 Kubernetes提供了Secret来处理敏感信息,目前Secret的类型有3种: Opaque(default): 任意字符串 kubernetes.io/s...
 [Kubernetes] kubernetes集群配置dns服务 日期:2018-05-09 11:46:21 点击:133 好评:0
[Kubernetes] kubernetes集群配置dns服务 日期:2018-05-09 11:46:21 点击:133 好评:0
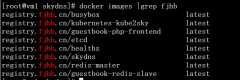
本文将在前文的基础上介绍在kubernetes集群环境中配置dns服务,在k8s集群中,pod的生命周期是短暂的,pod重启后ip地址会产生变化,对于应用程序来说这是不可接受的,为解决这个问题,K8S集群巧妙的引入的dns服务来实现服务的发现,在k8s集群中dns总共需要使...
 [Kubernetes] Kubernetes集群配置 日期:2018-05-09 11:44:53 点击:122 好评:0
[Kubernetes] Kubernetes集群配置 日期:2018-05-09 11:44:53 点击:122 好评:0
675人阅读 本文将介绍配置Kubernetes集群,kubernetes集群由master节点和slave节点组成。 Master节点上运行如下服务: etcd (etcd服务也可以单独运行,不一定要运行在Master节点上) kube-apiserver kube-controller-manager kube-scheduler Kubelet kube-prox...
 [Kubernetes] kubernetes集群环境准备工作 日期:2018-05-09 11:39:31 点击:194 好评:0
[Kubernetes] kubernetes集群环境准备工作 日期:2018-05-09 11:39:31 点击:194 好评:0
本文介绍学习kubernetes的环境相关准备工作,要进行kubernetes集群的学习我们至少需要两台主机,在本例中,我使用了两台VMware虚拟机完成了docker环境和flannel网络的配置工作。 k8s支持丰富的网络插件,通过网络插件实现不同主机上的docker容器网络互联互通...
 [Kubernetes] Kubernetes简要介绍 日期:2018-05-09 11:30:44 点击:143 好评:0
[Kubernetes] Kubernetes简要介绍 日期:2018-05-09 11:30:44 点击:143 好评:0
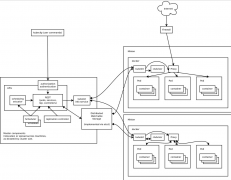
一、Kubernetes体系架构 Kubernetes是Google开源的容器集群管理系统,其提供应用部署、维护、 扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,其主要功能如下: 1) 使用Docker对应用程序包装(package)、实例化(instantiate)、运行(run)...
 [Kubernetes] K8S博文索引 日期:2018-05-09 11:15:48 点击:134 好评:0
[Kubernetes] K8S博文索引 日期:2018-05-09 11:15:48 点击:134 好评:0
近期花了比较多的时间研究和学习k8s,陆续写了一些博文。为方便阅读,顺手整理了个索引。希望对大家有所帮助,如有错误之处,烦请指出。 一、K8S 1.5.2篇 1、kubernetes简要介绍 http://blog.51cto.com/ylw6006/2066287 2、kubernetes集群环境准备工作 http:/...
 [Kubernetes] K8S集群基于heapster的HPA测试 日期:2018-05-09 11:13:10 点击:76 好评:0
[Kubernetes] K8S集群基于heapster的HPA测试 日期:2018-05-09 11:13:10 点击:76 好评:0
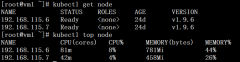
本文将介绍基于heapster获取metric的HPA配置。在开始之前,有必要先了解一下K8S的HPA特性。 1、HPA全称Horizontal Pod Autoscaling,即pod的水平自动扩展。 自动扩展主要分为两种,其一为水平扩展,针对于实例数目的增减;其二为垂直扩展,即单个实例可以使用...
 [Kubernetes] K8S使用dashboard管理集群 日期:2018-05-09 11:07:58 点击:50 好评:0
[Kubernetes] K8S使用dashboard管理集群 日期:2018-05-09 11:07:58 点击:50 好评:0
今年3月份在公司的内部k8s培训会上,开发同事表示使用dashboard的可以满足日常开发需求,例如查看pod的日志,执行exec指令,查看pod的运行状态等,但对basic认证的权限控制表示担忧。 之前介绍过在1.5.2版本上部署dashboard服务,在1.9.1版本离线部署中,也介...
[Hadoop] 伪Hadoop伪分布式集群搭建 日期:2018-04-27 14:43:35 点击:54 好评:0
Hadoop伪分布式 一、准备工作 1、关闭防火墙 service iptables start 立即开启防火墙,但是重启后失效。 service iptables stop 立即关闭防火墙,但是重启后失效。 如下命令是永久性操作,重启后生效。 chkconfig iptables on 开启防火墙,重启后生效。 chkc...
[Hadoop] Hadoop完全分布式配置 日期:2018-04-27 14:41:04 点击:97 好评:0
Hadoop完全分布式配置 一、 介绍 Hadoop2.0中,2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Nnetwork File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...
一、 Apache、Tomcat集群和负载均衡所需资源软件(附下载地址): a) apache_2.0.55-win...
不对的地方,欢迎大家拍砖。 现在有如下三台服务器: 10.57.22.201(做负载均衡配制)(...
一、试验拓扑 二、环境描述 负载均衡器: eth0 192.168.152.139 VIP : 192.168.152.2...