 [Memcached] Nginx+Tomcat7+Mencached负载均衡集群部署笔记 日期:2016-05-20 20:24:15 点击:146 好评:0
[Memcached] Nginx+Tomcat7+Mencached负载均衡集群部署笔记 日期:2016-05-20 20:24:15 点击:146 好评:0
Nginx+Tomcat+Memcached负载均衡集群服务搭建 操作系统:CentOS6.5 本文档主要讲解,如何在CentOS6.5下搭建Nginx+Tomcat+Memcached负载均衡集群服务器,Nginx负责负载均衡,Tomcat负责实际服务,Memcached负责同步Tomcat的Session,达到Session共享的目的。...
 [Memcached] Memcached分布式部署方案设计(含PHP代码) 日期:2016-05-20 20:23:41 点击:142 好评:0
[Memcached] Memcached分布式部署方案设计(含PHP代码) 日期:2016-05-20 20:23:41 点击:142 好评:0
一台Memcache通常不能满足我们的需求,这就需要分布式部署。Memcached分布式部署方案通常会采用两种方式,一种是普通Hash分布,一种是一致性Hash分布。本篇将以PHP作为客户端,来分析两种方案。 一、普通Hash分布: ?phpfunction test($key=name){ $md5 = su...
 [Memcached] Nginx+Tomcat7+Mencached负载均衡集群部署笔记 日期:2016-05-20 20:23:30 点击:181 好评:0
[Memcached] Nginx+Tomcat7+Mencached负载均衡集群部署笔记 日期:2016-05-20 20:23:30 点击:181 好评:0
Nginx+Tomcat+Memcached负载均衡集群服务搭建 操作系统:CentOS6.5 本文档主要讲解,如何在CentOS6.5下搭建Nginx+Tomcat+Memcached负载均衡集群服务器,Nginx负责负载均衡,Tomcat负责实际服务,Memcached负责同步Tomcat的Session,达到Session共享的目的。...
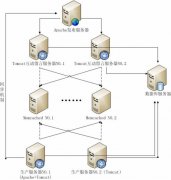 [Memcached] Apache+Tomcat+Memcached共享Session的构架设计 日期:2016-05-20 20:21:30 点击:57 好评:0
[Memcached] Apache+Tomcat+Memcached共享Session的构架设计 日期:2016-05-20 20:21:30 点击:57 好评:0
网站集群部署解决方案 一、方案目标 实现互动留言系统、后台发布系统的高可用性,有效解决高并发量对单台应用服务器的冲击,确保应用服务器单点故障不影响系统正常运行。 二、部署架构 采取Tomcat集群的部署方式,Apache通过proxy_module代理方式对用户的请...
[Memcached] nginx+tomcat+memcache集群部署 日期:2016-05-20 20:20:32 点击:107 好评:0
简要说明:使用nginx做负载均衡;memcache做session共享 1.软件版本 nginx-1.7.3 memcached-1. 4.22 tomcat-7.0.43 2.nginx搭建负载均衡配置 编辑nginx/conf/nginx.conf 配置文件 添加负载均衡设置 upstream localhost{ server localhost:8082; server local...
 [Memcached] Memcached 集群部署 日期:2016-05-20 20:16:59 点击:85 好评:0
[Memcached] Memcached 集群部署 日期:2016-05-20 20:16:59 点击:85 好评:0
一.Memcached简介 Memcached是一个高性能的分布式内存对象缓存系统,Memcached的高性能源于两阶段哈希(two-stagehash)结构,Memcached基于一个存储键/值对的HashMap,减轻数据库负载,它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、...
[Hadoop] Hadoop的安装与配置及示例程序wordcount的运行 日期:2016-05-18 10:41:47 点击:121 好评:0
前言 最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。具体安装及配置过程如下: 1 机器配置说明...
 [Hadoop] 超详细单机版搭建hadoop环境图文解析 日期:2016-05-18 10:24:29 点击:173 好评:0
[Hadoop] 超详细单机版搭建hadoop环境图文解析 日期:2016-05-18 10:24:29 点击:173 好评:0
年前,在老大的号召下,我们纠集了一帮人搞起了hadoop,并为其取了个响亮的口号云在手,跟我走。大家几乎从零开始,中途不知遇到多少问题,但终 于在回家之前搭起了一个拥有12台服务器的集群,并用命令行在该集群上运行了一些简单的mapreduce程序。想借此总...
[负载均衡SLB] linux服务器之LVS、Nginx和HAProxy负载均衡器对比总结 日期:2016-05-17 10:21:29 点击:178 好评:0
LVS特点: 1.抗负载能力强,使用IP负载均衡技术,只做分发,所以LVS本身并没有多少流量产生; 2.稳定性、可靠性好,自身有完美的热备方案;(如:LVS+Keepalived) 3.应用范围比较广,可以对所有应用做负载均衡; 4.不支持正则处理,不能做动静分离。 常用四...
[服务器集群] CentOS7.0上部署kubernetes集群 日期:2016-05-16 22:28:08 点击:65 好评:0
一.部署环境及架构 OpenStack:恒天云3.4 操作系统:centos 7.0 flannel: 0.5.5 Kubernetes: 1.2.0 Etcd版本: 2.2.2 Docker版本: 1.18.0 集群信息: Role Hostname IP Address Master master 10.0.222.2 Node node1 10.0.222.3 Node node2 10.0.222.4 Node no...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...
一、 Apache、Tomcat集群和负载均衡所需资源软件(附下载地址): a) apache_2.0.55-win...
不对的地方,欢迎大家拍砖。 现在有如下三台服务器: 10.57.22.201(做负载均衡配制)(...
一、试验拓扑 二、环境描述 负载均衡器: eth0 192.168.152.139 VIP : 192.168.152.2...