 [Hadoop] Hadoop单机版安装,配置,运行 日期:2015-10-20 15:31:16 点击:126 好评:0
[Hadoop] Hadoop单机版安装,配置,运行 日期:2015-10-20 15:31:16 点击:126 好评:0
Hadoop是最近非常流行的东东啦,但是乍一看都觉得是集群的东东,其实在单机版上安装Hadoop也是可以的,并且安装好以后可以很方便的进行程序的调试,调试好程序以后再丢到集群中,放心的算吧,呵呵。。 本文说的是在ubuntu上hadoop的安装,其他的linux可以类...
[Hadoop] Hadoop分布式文件系统:架构和设计 日期:2015-10-17 02:54:14 点击:67 好评:0
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。...
[Hadoop] MapReduce应用 日期:2015-10-10 11:06:07 点击:63 好评:0
目录[-] 1、MapReduce实现矩阵相乘 2、MapReduce实现倒排索引 3、MapReduce实现复杂倒排索引 1、MapReduce实现矩阵相乘 一. 准备数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #!/bin/bash if[$#-ne3] then echotheremustb...
 [Hadoop] MapReduce简单使用 日期:2015-10-10 11:05:14 点击:186 好评:0
[Hadoop] MapReduce简单使用 日期:2015-10-10 11:05:14 点击:186 好评:0
目录[-] 1、启动hadoop工程 2、MapReduce统计文本单词数量 2、MapReduce排除文本重复数据 3、MapReduce实线文本数据的简单排序 4、MapReduce实线单表连接 1、启动hadoop工程 2、MapReduce统计文本单词数量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19...
 [Hadoop] 基本hadoop文件操作 日期:2015-10-10 11:03:24 点击:65 好评:0
[Hadoop] 基本hadoop文件操作 日期:2015-10-10 11:03:24 点击:65 好评:0
目录[-] 1、启动hadoop工程 2、eclipse导入插件 3、在Map/Reduce的窗口下建立连接(单机版) 4、创建工程,导入jar,配置文件 5、hadoop操作文件 1、启动hadoop工程 2、eclipse导入插件 将hadoop-eclipse-plugin-2.6.0.jar插件导入eclipse中,重启eclipse 3...
 [Hadoop] ubuntu14.04 安装hadoop 日期:2015-10-10 11:03:06 点击:195 好评:0
[Hadoop] ubuntu14.04 安装hadoop 日期:2015-10-10 11:03:06 点击:195 好评:0
目录[-] 1、下载hadoop,解压 2、配置.bashrc文件 4、配置hadoop-env.sh文件 5、配置mapred-site.xml文件 6、配置core-site.xml文件 7、配置yarn-site.xml文件 8、配置hdfs-site.xml文件 9、设置面密码登录 10、格式化hadoop数据 10、启动hadoop 11、查看had...
 [Hadoop] hadoop 网站日志分析 日期:2015-10-08 12:49:04 点击:190 好评:0
[Hadoop] hadoop 网站日志分析 日期:2015-10-08 12:49:04 点击:190 好评:0
一、项目要求 本文讨论的日志处理方法中的日志,仅指Web日志。其实并没有精确的定义,可能包括但不限于各种前端Web服务器apache、lighttpd、nginx、tomcat等产生的用户访问日志,以及各种Web应用程序自己输出的日志。 二、需求分析: KPI指标设计 PV(PageVie...
[Hadoop] hadoop-双色球-统计 日期:2015-10-08 12:06:47 点击:79 好评:0
1/使用hadoop把双色球相邻的红球进行统计: 测试数据在:http://pan.baidu.com/s/1hq82YrU 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55...
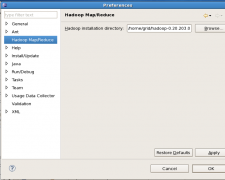 [Hadoop] 基于Eclipse的Hadoop应用开发环境配置 日期:2015-10-08 12:06:43 点击:189 好评:0
[Hadoop] 基于Eclipse的Hadoop应用开发环境配置 日期:2015-10-08 12:06:43 点击:189 好评:0
基于Eclipse的Hadoop应用开发环境配置 我的开发环境: 操作系统centos5.5 一个namenode 两个datanode Hadoop版本:hadoop-0.20.203.0 Eclipse版本:eclipse-java-helios-SR2-linux-gtk.tar.gz(使用3.7的版本总是崩溃,让人郁闷) 第一步:先启动hadoop守护进...
[Hadoop] Hadoop Namenode不能启动 dfs/name is in an inconsistent 日期:2015-10-08 12:05:42 点击:88 好评:0
前段时间自己的本机上搭的Hadoop环境(按文档的伪分布式),第一天还一切正常,后来发现每次重新开机以后都不能正常启动,在start-dfs.sh之后jps一下发现namenode不能正常启动,按提示找到logs目录下namenode的启动log发现如下异常 org.apache.hadoop.hdfs.s...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...