 [Hadoop] Hadoop DistributedCache分布式缓存的使用 日期:2016-05-21 14:35:45 点击:127 好评:0
[Hadoop] Hadoop DistributedCache分布式缓存的使用 日期:2016-05-21 14:35:45 点击:127 好评:0
做项目的时候遇到一个问题,在Mapper和Reducer方法中处理目标数据时,先要去检索和匹配一个已存在的标签库,再对所处理的字段打标签。因为标签库不是很大,没必要用HBase。我的实现方法是把标签库存储成HDFS上的文件,用分布式缓存存储,这样让每个slave都能...
[Hadoop] Hadoop的安装与配置及示例程序wordcount的运行 日期:2016-05-18 10:41:47 点击:121 好评:0
前言 最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。具体安装及配置过程如下: 1 机器配置说明...
 [Hadoop] 超详细单机版搭建hadoop环境图文解析 日期:2016-05-18 10:24:29 点击:173 好评:0
[Hadoop] 超详细单机版搭建hadoop环境图文解析 日期:2016-05-18 10:24:29 点击:173 好评:0
年前,在老大的号召下,我们纠集了一帮人搞起了hadoop,并为其取了个响亮的口号云在手,跟我走。大家几乎从零开始,中途不知遇到多少问题,但终 于在回家之前搭起了一个拥有12台服务器的集群,并用命令行在该集群上运行了一些简单的mapreduce程序。想借此总...
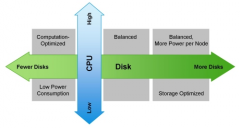 [Hadoop] Hadoop 硬件规划 日期:2016-05-16 10:51:38 点击:121 好评:0
[Hadoop] Hadoop 硬件规划 日期:2016-05-16 10:51:38 点击:121 好评:0
Hadoop近几年一直很热门,市面上有各种各样的书籍以及培训机构,当你熟悉完这些准备在生产上运行自己的第一个生产Hadoop集群的时候,就需要考虑购买什么样的硬件了,专业人士肯定会说:这要看你的业务类型和负载了,当然这是很有道理的,但是我接触的很多企业...
[Hadoop] hadoop启动namenode失败 日期:2016-04-08 01:03:33 点击:63 好评:0
启动hadoop的namenode时,报错: ERRORorg apache. Hadoop. HDFS. Server. The namenode. The namenode: Java. Lang. IllegalArgumentException: Does not contain a valid host: port authority: HDFS: / / hadoop_forged: 9000 原因分析: 一般都是配置文...
[Hadoop] 在 Apache Hive 中轻松生存的12个技巧 日期:2016-04-08 00:23:14 点击:89 好评:0
Hive 可以让你在 Hadoop 上使用 SQL,但是在分布式系统上优化 SQL 则有所不同。这里是让你可以轻松驾驭 Hive 的12个技巧。 Hive并不是关系型数据库(RDBMS),但是它大多数时候都表现得像是一个关系型数据库一样,它有表、可以运行 SQL、也支持 JDBC 和 ODBC...
[Hadoop] Hadoop缺省端口列表 日期:2016-03-19 17:58:40 点击:129 好评:0
50030 mapred.job.tracker.http.address 描述:JobTracker administrative web GUI JOBTRACKER的HTTP服务器和端口 50070 dfs.http.address 描述:NameNode administrative web GUI NAMENODE的HTTP服务器和端口 50010 dfs.datanode.address 描述:DataNode co...
[Hadoop] HADOOP常见错误 日期:2016-03-19 17:57:59 点击:155 好评:0
错误1:bin/hadoop dfs 不能正常启动,持续提示: INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 0 time(s). 原因:由于 dfs 的部分文件默认保存在tmp文件夹,在系统重启时被删除。 解决:修改core-site.xml 的 had...
[Hadoop] HADOOP报错Incompatible namespaceIDs 日期:2016-03-19 17:57:16 点击:118 好评:0
今早一来,突然发现使用-put命令往HDFS里传数据传不上去了,抱一大堆错误,然后我使用bin/hadoop dfsadmin -report查看系统状态 admin@adw1:/home/admin/joe.wangh/hadoop-0.19.2bin/hadoop dfsadmin -report Configured Capacity: 0 (0 KB) Present Capacit...
[Hadoop] hadoop0.19.0版的包和类的分析 日期:2016-03-11 23:20:51 点击:51 好评:0
1Hadoop包总量(15个包) 15个包,分下面几类: (1)配置文件:这是一个多方共享的话,让每个人可以告诉群里每个人我想干啥,由控制者根据配置文件去找相应的实体指向。 (2)共用工具:基础功能的提供者 (3)通讯工具:大家是基于通讯进行工作的 (4)基...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...