 [Hadoop] Hadoop完全分布式搭建 日期:2017-02-05 23:35:28 点击:56 好评:0
[Hadoop] Hadoop完全分布式搭建 日期:2017-02-05 23:35:28 点击:56 好评:0
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。 对于Hadoop的集群来讲,...
 [Hadoop] CentOS7安装Hadoop2.7完整流程 日期:2017-02-05 22:27:28 点击:65 好评:0
[Hadoop] CentOS7安装Hadoop2.7完整流程 日期:2017-02-05 22:27:28 点击:65 好评:0
总体思路,准备主从服务器,配置主服务器可以无密码SSH登录从服务器,解压安装JDK,解压安装Hadoop,配置hdfs、mapreduce等主从关系。 1、环境,3台CentOS7,64位,Hadoop2.7需要64位Linux,CentOS7 Minimal的ISO文件只有600M,操作系统十几分钟就可以安装完...
[Hadoop] Hadoop 1.2.1 集群安装一 日期:2016-12-24 17:42:08 点击:197 好评:0
1:安装Linux 2:修改机器名 hostname 显示主机名 [it@localhost bin]$ hostname localhost.sohudo 编辑主机名配置文件 [it@localhost bin]$ vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=localhost.sohudo 用root登录 [it@localhost bin]$ su - 密码...
[Hadoop] Hadoop1.2.1集群安装二 日期:2016-12-24 17:40:46 点击:172 好评:0
1:安装JDK 下载好jdk-7u45-Linux-x64.gz 或从其它电脑copy过去 [it@feng01 ~]$scp -r ./jdk-7u45-linux-x64.gz it@it.net.cn:/home/it The authenticity of host it.net.cn (10.3.7.214) cant be established. RSA key fingerprint is a8:9d:34:63:fa:c2:47:...
[Hadoop] Hadoop1.2.1集群安装三 日期:2016-12-24 17:36:01 点击:181 好评:0
配置Hadoop 1:下载hadoop-1.2.1.tar.gz 在/home/it 创建目录 mkdir hadoop 2:解压 [it@it.net.cn hadoop]$ ls hadoop-1.2.1.tar.gz [it@it.net.cn hadoop]$ tar zxf hadoop-1.2.1.tar.gz [it@it.net.cn hadoop]$ ls hadoop-1.2.1 hadoop-1.2.1.tar.gz [it@it....
[Hadoop] hadoop 2.4.1 集群安装一 日期:2016-12-24 17:34:37 点击:92 好评:0
配置主机名参考 Hadoop 1.2.1 集群安装一 配置JDK环境参考Hadoop1.2.1集群安装二 配置Hadoop A:下载解压hadoop http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.4.1/hadoop-2.4.1.tar.gz 在/home/it 创建目录 mkdir hadoop hadoop-2.4.1.tar.gz下载...
 [Hadoop] hadoop 2.4.1 集群安装二 日期:2016-12-24 17:31:34 点击:98 好评:0
[Hadoop] hadoop 2.4.1 集群安装二 日期:2016-12-24 17:31:34 点击:98 好评:0
1:创建目录 [plain]view plaincopy [jifeng@feng01hadoop]$mkdirtmp [jifeng@feng01hadoop]$mkdirname [jifeng@feng01hadoop]$mkdirdata [jifeng@feng01hadoop]$ls datahadoop-1.2.1.tar.gzhadoop-2.4.1.tar.gz hadoop-1.2.1hadoop-2.4.1name hadoop-1.2.1-...
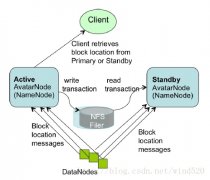 [Hadoop] Hadoop中Namenode单点故障的解决方案及详细介绍 日期:2016-12-24 17:10:55 点击:135 好评:0
[Hadoop] Hadoop中Namenode单点故障的解决方案及详细介绍 日期:2016-12-24 17:10:55 点击:135 好评:0
正如大家所知,NameNode在Hadoop系统中存在单点故障问题,这个对于标榜高可用性的Hadoop来说一直是个软肋。本文讨论一下为了解决这个问题而存在的几个solution。 1. Secondary NameNode 原理:Secondary NN会定期的从NN中读取editlog,与自己存储的Image进行...
 [Hadoop] 编译hadoop的eclipse插件hadoop-eclipse-plugin-1.2.1.jar 日期:2016-12-24 17:07:58 点击:171 好评:0
[Hadoop] 编译hadoop的eclipse插件hadoop-eclipse-plugin-1.2.1.jar 日期:2016-12-24 17:07:58 点击:171 好评:0
1:下载后Hadoop-1.1.2.tar.gz文件,里面包含源代码,并解压到E:\hadoop\hadoop-1.2.1 2:在eclipse导入工程,目录选择:E:\hadoop\hadoop-1.2.1\src\contrib\eclipse-plugin 3:在项目 MapReduceTools 中新建 lib 目录,将 hadoop-1.2.1 下的 hadoop-core-1...
[Hadoop] 大数据集群环境ambari支持集群管理监控,供应hadoop+hbase+zookeeper 日期:2016-12-17 23:14:16 点击:78 好评:0
大数据集群环境ambari支持集群管理监控,供应hadoop+hbase+zookeeper Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...