 [Hadoop] MapReduce 中的两表 join 几种方案简介 日期:2016-11-27 02:37:50 点击:132 好评:0
[Hadoop] MapReduce 中的两表 join 几种方案简介 日期:2016-11-27 02:37:50 点击:132 好评:0
1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的。而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的技巧。 本文首先介绍了Hadoop上通常的JOIN实现方法,然后给出了几种针对不同...
[Hadoop] MapReduce中的自定义多目录/文件名输出HDFS 日期:2016-11-27 02:37:19 点击:105 好评:0
最近考虑到这样一个需求: 需要把原始的日志文件用hadoop做清洗后,按业务线输出到不同的目录下去,以供不同的部门业务线使用。 这个需求需要用到MultipleOutputFormat和MultipleOutputs来实现自定义多目录、文件的输出。 需要注意的是,在hadoop 0.21.x之前...
[Hadoop] 使用 FileSystem JAVA API 对 HDFS 进行读、写、删除等操作 日期:2016-11-27 02:36:37 点击:63 好评:0
Hadoop文件系统 基本的文件系统命令操作, 通过hadoop fs -help可以获取所有的命令的详细帮助文件。 Java抽象类org.apache.hadoop.fs.FileSystem定义了hadoop的一个文件系统接口。该类是一个抽象类,通过以下两种静态工厂方法可以过去FileSystem实例: public...
[Hadoop] MapReduce:默认Counter的含义 日期:2016-11-27 02:35:46 点击:56 好评:0
MapReduce Counter为提供我们一个窗口:观察MapReduce job运行期的各种细节数据。今年三月份期间,我曾经专注于MapReduce性能调优工作,是否优化的绝大多评估都是基于这些Counter的数值表现。MapReduce自带了许多默认Counter,可能有些朋友对它们有些疑问,现...
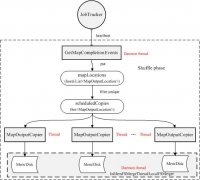 [Hadoop] Hadoop中shuffle阶段流程分析 日期:2016-11-27 02:33:15 点击:162 好评:0
[Hadoop] Hadoop中shuffle阶段流程分析 日期:2016-11-27 02:33:15 点击:162 好评:0
宏观上,Hadoop每个作业要经历两个阶段:Map phase和reduce phase。对于Map phase,又主要包含四个子阶段:从磁盘上读数据-》执行map函数-》combine结果-》将结果写到本地磁盘上;对于reduce phase,同样包含四个子阶段:从各个map task上读相应的数据(shuf...
[Hadoop] Pig、Hive、MapReduce 解决分组 Top K 问题 日期:2016-11-27 02:31:09 点击:55 好评:0
问题: 有如下数据文件 city.txt (id, city, value) cat city.txt 1 wh 500 2 bj 600 3 wh 100 4 sh 400 5 wh 200 6 bj 100 7 sh 200 8 bj 300 9 sh 900 需要按 city 分组聚合,然后从每组数据中取出前两条value最大的记录。 1、这是实际业务中经常会遇...
[Hadoop] hadoop 里执行 MapReduce 任务的几种常见方式 日期:2016-11-27 02:27:11 点击:138 好评:0
说明: 测试文件: echo -e aa\tbb \tcc\nbb\tcc\tdd 3.txt hadoop fs -put 3.txt /tmp/3.txt 全文的例子均以该文件做测试用例,统计单词出现的次数(WordCount)。 1、原生态的方式:java 源码编译打包成jar包后,由 hadoop 脚本调度执行,举例: import ja...
[Hadoop] 机器重启hadoop报错:FSNamesystem initialization failed 日期:2016-11-27 02:26:09 点击:59 好评:0
1. 基本信息 hadoop 版本 hadoop-0.20.205.0.tar.gz 操作系统 ubuntu 2. 问题 在使用Hadoop开发初期的时候遇到一个问题。 每次重启系统后发现不能正常运行hadoop。必须执行 bin/hadoop namenode -format 进行格式化才能成功运行hadoop,但是也就意味着以前记...
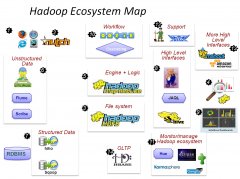 [Hadoop] Hadoop生态图谱 日期:2016-11-27 02:25:30 点击:79 好评:0
[Hadoop] Hadoop生态图谱 日期:2016-11-27 02:25:30 点击:79 好评:0
当下Hadoop已经成长为一个庞大的体系,貌似只要和海量数据相关的,没有哪个领域缺少Hadoop的身影,下面是一个Hadoop生态系统的图谱,详细的列举了在Hadoop这个生态系统中出现的各种数据工具。 这一切,都起源自Web数据爆炸时代的来临 数据抓取系统 - Nutch...
 [Hadoop] HDFS的架构和设计要点 日期:2016-11-27 02:23:26 点击:61 好评:0
[Hadoop] HDFS的架构和设计要点 日期:2016-11-27 02:23:26 点击:61 好评:0
虽然本文已经比较旧远了,但是在很多方面还是有一定学习的价值,中文版译者为 killme 。 一、前提和设计目标 硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...