 [Hadoop] 从 secondarynamenode 中恢复 namenode 日期:2016-11-27 02:10:36 点击:99 好评:0
[Hadoop] 从 secondarynamenode 中恢复 namenode 日期:2016-11-27 02:10:36 点击:99 好评:0
1.修改conf/core-site.xml,增加 Xml代码 property namefs.checkpoint.period/name value3600/value descriptionThenumberofsecondsbetweentwoperiodiccheckpoints./description /property property namefs.checkpoint.size/name value67108864/value descrip...
[Hadoop] 使用hadoop进行大规模数据的全局排序 日期:2016-11-27 02:08:50 点击:120 好评:0
1. Hellow hadoop~~! Hadoop(某人儿子的一只虚拟大象的名字)是一个复杂到极致,又简单到极致的东西。 说它复杂,是因为一个hadoop集群往往有几十台甚至成百上千台low cost的计算机组成,你运行的每一个任务都要在这些计算机上做任务的分发,执行中间数据排...
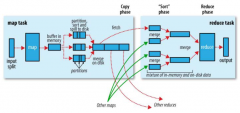 [Hadoop] MapReduce: 详解 Shuffle 过程 日期:2016-11-27 02:06:54 点击:121 好评:0
[Hadoop] MapReduce: 详解 Shuffle 过程 日期:2016-11-27 02:06:54 点击:121 好评:0
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce, Shuffle是必须要了解的。我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑,反而越搅越混。前段时间在做MapReduce job 性能调优的工作,需要深入代码研究...
 [Hadoop] 深入理解Hadoop集群和网络 日期:2016-11-27 02:02:14 点击:105 好评:0
[Hadoop] 深入理解Hadoop集群和网络 日期:2016-11-27 02:02:14 点击:105 好评:0
摘要:本文将着重于讨论Hadoop集群的体系结构和方法,及它如何涉及到网络和服务器基础设施。开始我们先学习一下Hadoop集群运作的基...
[Hadoop] hadoop集群增加/删除节点 日期:2016-11-27 02:01:20 点击:69 好评:0
hadoop要发到每个节点的配置文件,只有core-site.xml mapred-site.xml hdfs-site.xml 添加节点 1.修改host 和普通的datanode一样。添加namenode的ip 2.修改namenode的配置文件conf/slaves 添加新增节点的ip或host 3.在新节点的机器上,启动服务 [root@slave-...
[Hadoop] hadoop HDFS详解 日期:2016-11-27 02:00:20 点击:87 好评:0
一、HDFS的基本概念 1.1、数据块(block) HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。 和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的...
[Hadoop] hive 的 简单操作语句 日期:2016-10-06 19:36:55 点击:85 好评:0
简单的创建表 create table table_name ( id int, dtDontQuery string, name string) 创建有分区的表 create table table_name ( id int, dtDontQuery string, name string)partitioned by (date string) 一个表可以拥有一个或者多个分区,每个分区以文件夹...
[Hadoop] Hadoop 的命令笔记 日期:2016-10-06 19:36:30 点击:164 好评:0
bin/hadoop jar /home/***/secure_hadoop_project.jar package.OldInfoMerge /merges/old.txt /merges/tmp1 查看根目录的列表 bin/hadoop fs -lsr / 单节点启动 5)重启namenode sudo -u hdfs /usr/lib/hadoop/bin/hadoop-daemon.sh --config /etc/hadoop/conf...
 [Hadoop] Hadoop2 基本配置教程 日期:2016-10-06 19:36:03 点击:88 好评:0
[Hadoop] Hadoop2 基本配置教程 日期:2016-10-06 19:36:03 点击:88 好评:0
本文为安装指导,在安装过程中,我们可以注意一下问题: 1.当有多个HDFS集群同时工作时,用户如果不写集群名称,那么默认使用哪个?通过那个文件来进行配置? 2.NameNode、DataNode、JournalNode等存放数据的默认公共目录在什么位置? 3.那个文件可以配置Zoo...
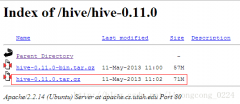 [Hadoop] Hive 安装 日期:2016-10-06 19:32:55 点击:129 好评:0
[Hadoop] Hive 安装 日期:2016-10-06 19:32:55 点击:129 好评:0
1 、下载Hive-0.11.0 http://apache.cs.utah.edu/hive/hive-0.11.0/ 2、解压安装 Hive原则上可以安装在集群上的任何一台机器上面,但是考虑到 master节点的负荷比较大,我们选择一台机器性能较好的datanode来安装hive。在我们的集群中选择cloud003来安装hive...
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个...